LogicTronix is developing high-performance custom CNN accelerator RTL IP tailored for vision-based machine learning workloads on FPGA platforms.
- This accelerator is designed with a focus on low latency, high throughput, and efficient resource utilization, enabling real-time image classification, object detection, and advanced vision analytics directly at the edge.
- By leveraging optimized dataflow architectures and hardware-friendly neural network designs, LogicTronix ensures scalable and power-efficient deployment across AMD-Xilinx FPGA platforms, ranging from low-power Artix series devices to ultra-high-density, high-throughput Versal architectures, enabling optimized solutions for both edge and high-performance computing applications.
In parallel, LogicTronix is expanding its capabilities into next-generation Edge AI and Physical AI solutions and LLM acceleration using MPSoC and Versal platforms.
- This solution target intelligent systems that require on-device processing, reduced cloud dependency, and faster decision-making. With the integration of AI engines, programmable logic, and embedded processors.
- LogicTronix delivers end-to-end acceleration frameworks capable of supporting both vision ML and large model inference for applications in automotive, robotics, autonomous systems, and industrial AI.
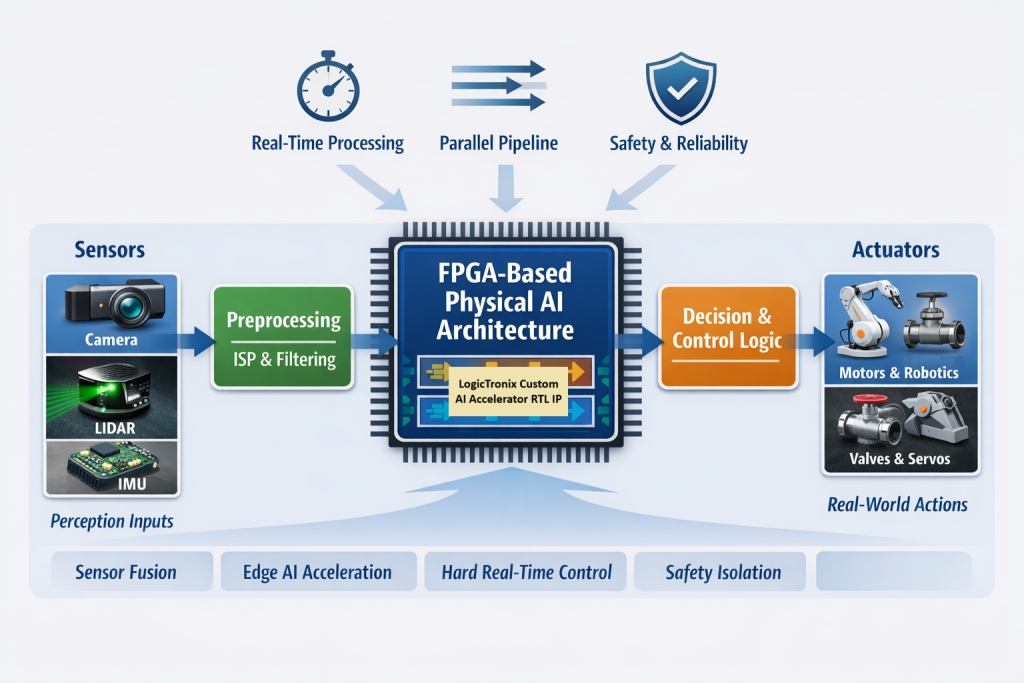
Figure – LogicTronix custom AI Accelerator RTL IP solution with AMD-Xilinx FPGA for Physical AI application